MINER: Multiscale Implicit Neural Representation
ECCV 2022
Vishwanath Saragadam, Jasper Tan, Guha Balakrishnan,
Richard G. Baraniuk, Ashok Veeraraghavan
Abstract
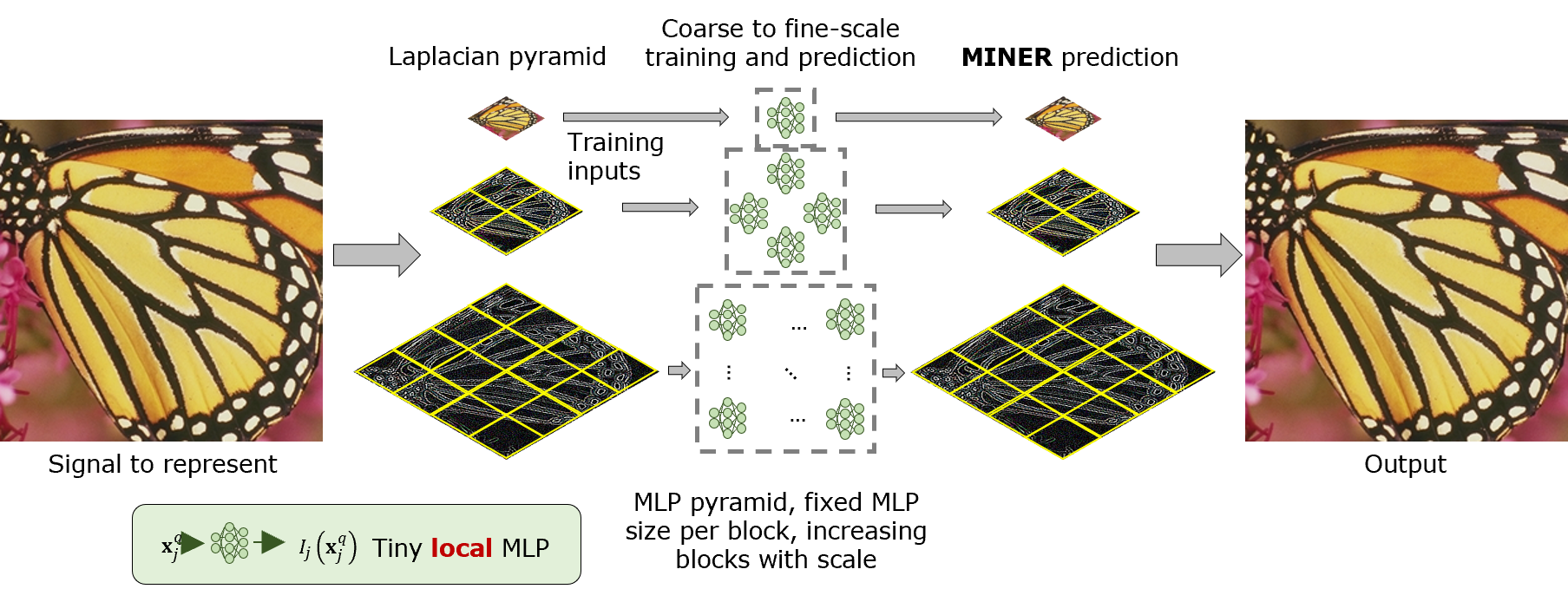
We introduce a new neural signal representation designed for the efficient high-resolution representation of large-scale signals. The key innovation in our multiscale implicit neural representation (MINER) is an internal representation via a Laplacian pyramid, which provides a sparse multiscale representation of the signal that captures orthogonal parts of the signal across scales. We leverage the advantages of the Laplacian pyramid by representing small disjoint patches of the pyramid at each scale with a tiny MLP. This enables the capacity of the network to adaptively increase from coarse to fine scales, and only represent parts of the signal with strong signal energy. The parameters of each MLP are optimized from coarse-to-fine scale which results in faster approximations at coarser scales, thereby ultimately an extremely fast training process. We apply MINER to a range of large-scale signal representation tasks, including gigapixel images and very large point clouds, and demonstrate that it requires fewer than 25% of the parameters, 33% of the memory footprint, and 10% of the computation time of competing techniques such as ACORN to reach the same representation error.
Image fitting

Gigapixel image fitting
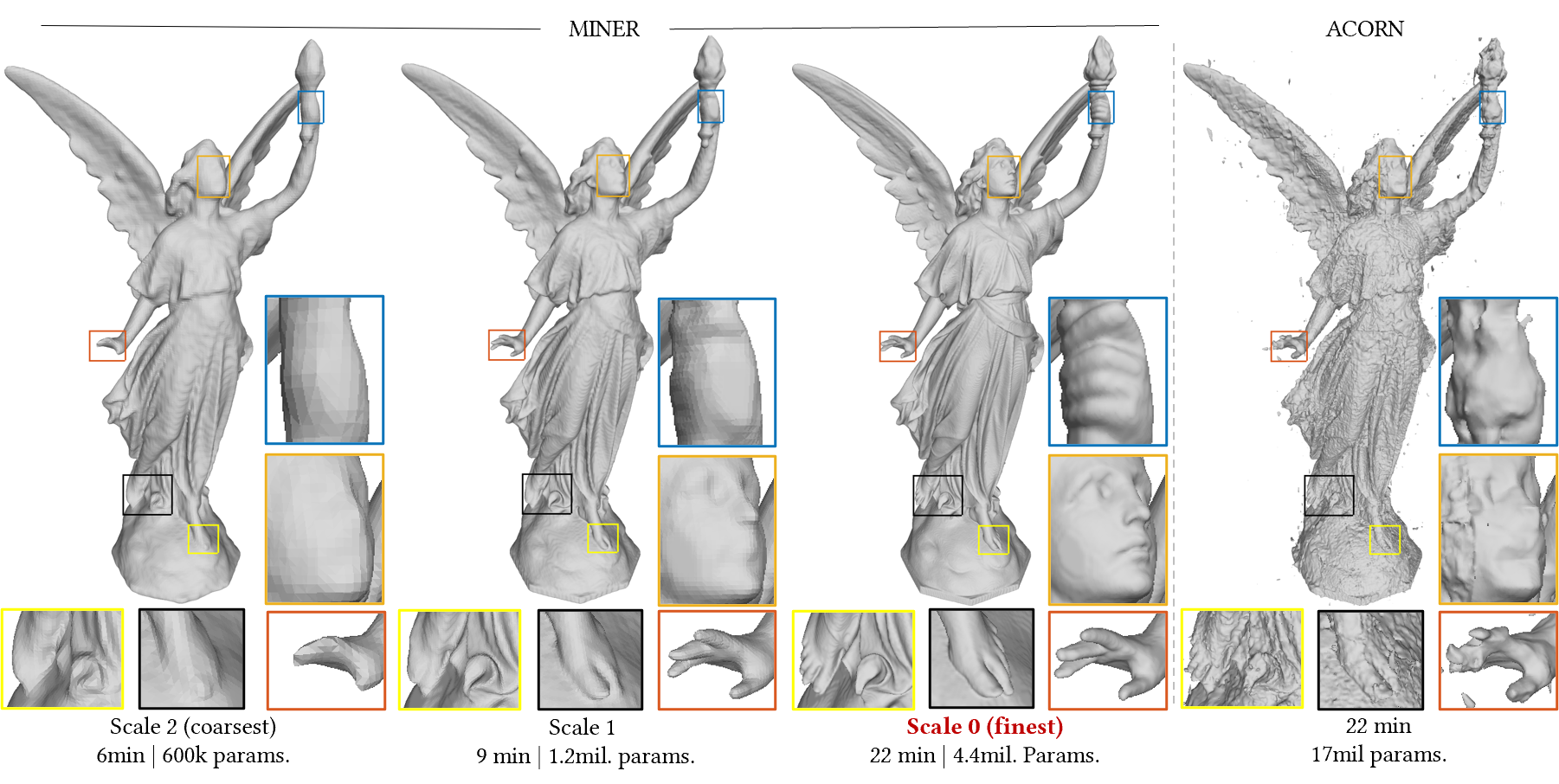
Fitting large 3D point clouds